维嘉优配平台 【刚刚,DeepSeek 又有新动作了!】 不过和模型没关系,更新了
【刚刚,DeepSeek 又有新动作了!】
不过和模型没关系,更新了一下 DeepGEMM 代码库。
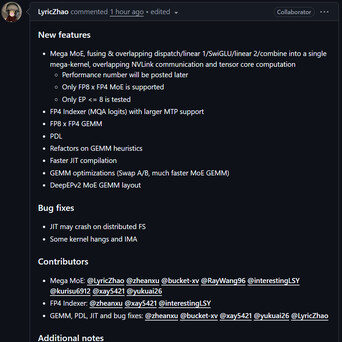
不过,此次更新,我们看到了一个新东西:Mega MoE。
链接:http://t.cn/AXMe5IMQ
根据相关信息,Mega MoE 来自 DeepSeek 基础设施团队的 Chenggang Zhao 等人。
简单说,它做的事情很直接,就是把原本被拆成多段执行的 MoE 流程,揉成一整个,在 GPU 上一次性跑完。
过去的 MoE 更像一条被切碎的流水线:dispatch、两层线性、SwiGLU、再 combine,每一步都是独立 kernel,中间还夹着频繁的跨卡通信。结果就是典型的低效节奏:算一会儿、等一会儿,传一会儿、再算一会儿。Mega MoE 的做法可以说是「直接焊死这条流水线」,不仅把所有步骤 fuse 成一个 mega-kernel,还让通信和计算同时发生,在 Tensor Core 运算的同时通过 NVLink 传数据,把等待时间尽可能吃掉。
但更值得注意的,是这次一整套工程侧的变化。DeepSeek 开始把很多原本藏在内部的调优能力开放出来,比如可以手动限制 SM 使用、控制 Tensor Core 利用率、开启或关闭 PDL 调度,以及干预 JIT 编译、对齐策略、block size 等细节。再加上一整套环境变量,连编译过程、PTX/SASS 输出、缓存策略都能控制。这种粒度更像是在调一台可以被精细操控的性能机器。
放在一起看,这次更新其实指向一个很明确的方向:DeepSeek 正在把 MoE 从「理论上很优雅,但工程上很折腾」的结构,往「可以稳定、高效跑在大规模系统上的基础设施」推进。
而 Mega MoE 很可能只是这个大方向的一块拼图;就是不知道这块拼图是不是 DeepSeek-V4 的一部分?

网眼查提示:文章来自网络,不代表本站观点。